本文目的
上一章节已经详细的向大家介绍过排序的相关概念(详见学习笔记-排序简单介绍) ,本文旨在为大家详细的介绍基数排序。
基数排序
基数排序(radix sort)属于"分配式排序"(distribution sort),又称"桶子法"(bucket sort)或bin sort,顾名思义,它是透过键值的部份资讯,将要排序的至某些"桶"中,以达到排序的作用,基数排序法是属于稳定性的排序,在某些时候,基数排序法的效率高于其它的稳定性排序法。
基本思想
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
实现方法
最高位优先(Most Significant Digit first)法,简称MSD法:先按k1排序分组,同一组中记录,关键码k1相等,再对各组按k2排序分成子组,之后,对后面的关键码继续这样的排序分组,直到按最次位关键码kd对各子组排序后。再将各组连接起来,便得到一个有序序列。
最低位优先(Least Significant Digit first)法,简称LSD法:先从kd开始排序,再对kd-1进行排序,依次重复,直到对k1排序后便得到一个有序序列。
实现原理
基数排序的发明可以追溯到1887年赫尔曼·何乐礼在打孔卡片制表机(Tabulation Machine)上的贡献。它是这样实现的:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序的方式可以采用LSD(Least significant digital)或MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。
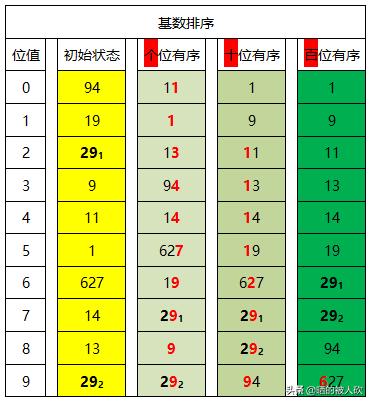
排序示例
在下图中,从最低位开始,依次进行排序。
1,按照个位数进行排序。
2,按照十位数进行排序。
3,按照百位数进行排序。
算法实现
#include #define elemType int /*元素类型*/#define MAX 10 //元素个数 int k=1;//轮次记录 //打印函数 void Print (elemType arr[], int len){int i;for (i=0; i m) { m = a[i]; } } while (m / exp > 0) { int bucket[MAX] = { 0 }; for (i = 0; i < n; i++) { bucket[(a[i] / exp) % MAX]++; } for (i = 1; i < MAX; i++) { bucket[i] += bucket[i - 1]; } for (i = n - 1; i >= 0; i--) { b[--bucket[(a[i] / exp) % MAX]] = a[i]; } for (i = 0; i < n; i++) { a[i] = b[i]; } exp *= MAX; printf("第===%d===轮排序后结果如下:",k);Print (a, MAX);k=k+1; }}void main() {int i; elemType arr[MAX] = {94,19,29,9,11,1,627,14,13,29}; printf("待排序的序列为:"); Print(arr, MAX); printf(""); Sort (arr,10); printf(""); printf("排好序的结果如下:"); Print(arr, MAX); }
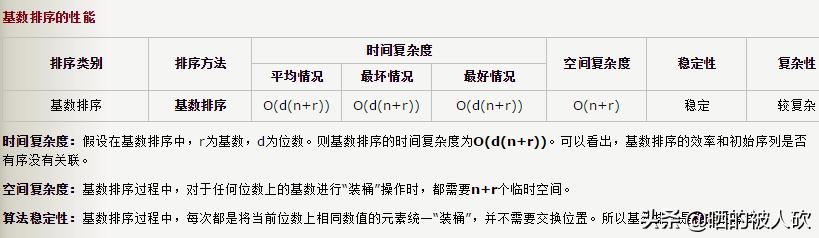
算法分析
初看起来,基数排序的执行效率似乎好的让人无法相信,所有要做的只是把原始数据项从数组复制到链表,然后再复制回去。如果有10个数据项,则有20次复制,对每一位重复一次这个过程。假设对5位的数字排序,就需要205=100次复制。如果有100个数据项,那么就有2005=1000次复制。复制的次数与数据项的个数成正比,即O(n)。这是我们看到的效率最高的排序算法。
不幸的是,数据项越多,就需要更长的关键字,如果数据项增加10倍,那么关键字必须增加一位(多一轮排序)。复制的次数和数据项的个数与关键字长度成正比,可以认为关键字长度是N的对数。因此在大多数情况下,基数排序的执行效率倒退为O(N*logN),和快速排序差不多。具体总结如下图。
本文的初衷为学习笔记的分享,部分图文来源于网络,如侵,联删。